
Databricks + Yellowbrick = Cost-efficient Workload Analytics
What if the data platform you bought to give everyone access to insights is actually doing the opposite?
Many companies modernize their data platforms expecting better performance, lower costs, and everyone to have access. And even with top-tier Data Platforms challenges remain: fragmented tools, rising costs, and increasing pressure to make insights universally available.
The result? Data engineers must limit what data people can access and how much they can analyze to reduce costs — leaving the rest of the business waiting for insights.
Sounds familiar? You are not alone.
In this blog, we will focus on customers that have shared with us their stories about using Databricks, their challenges and the solution they are looking for.
The Big Problem Nobody Talks About
Databricks is a powerful tool for large-scale data ingestion, transformation, and advanced analytics. Its Medallion architecture—bronze, silver, and gold layers—provides a structured path from raw data to actionable business insights.
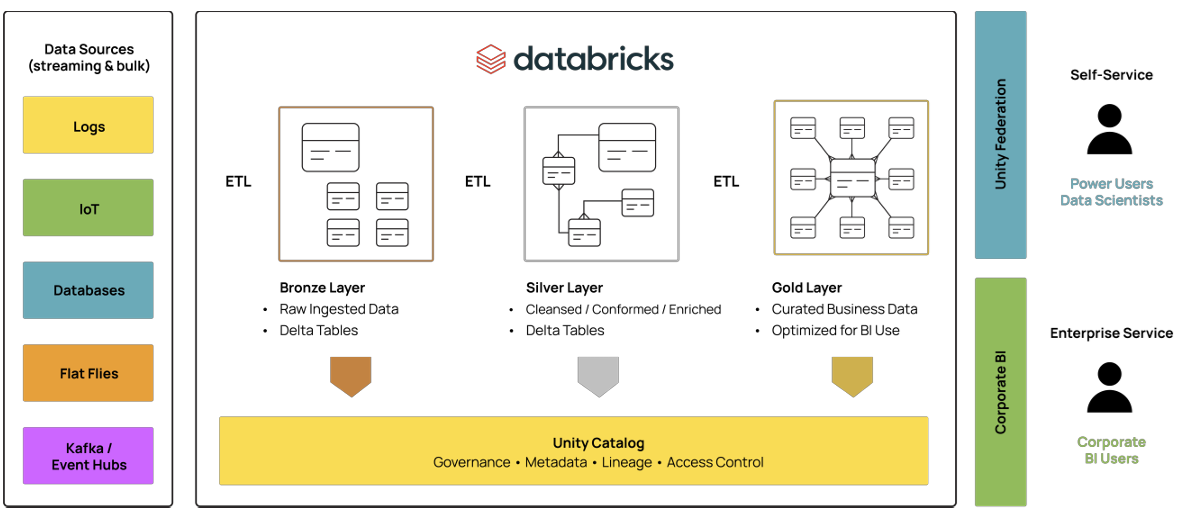
But for many companies, when Business Intelligence (BI) workloads hit the gold layer, costs spike, access narrows, and performance drags. That leads to several problems:
- Shadow IT takes over. Each team uses the tools that are available to them; reports vary based on department and tool used, and no one can trust the data.
- Trade-offs and compromises become the norm. People are forced to choose between: High performance or reasonable costs, speed or staying in control; analyzing all your data or keeping budgets in check.
- Data becomes exclusive. Only a select few get access, while the rest submit tickets and wait.
The result? Teams cannot analyze all their data, and systems become too expensive and complex to manage. Yet the demand for insights has not gone away; business users still need answers. This forces IT and engineering teams to step in, diverting their time to support insight requests instead of focusing on core projects.
Does this have to stay like that? NO … These are symptoms of an architecture problem that can be solved.
The Solution: Augment, Not Replace
What if you can keep your Databricks investment and make it work the way you want? Use Databricks where it performs best, handling raw data ingestion and transformation, while offloading expensive analytics to a platform optimized for performance and cost efficiency.
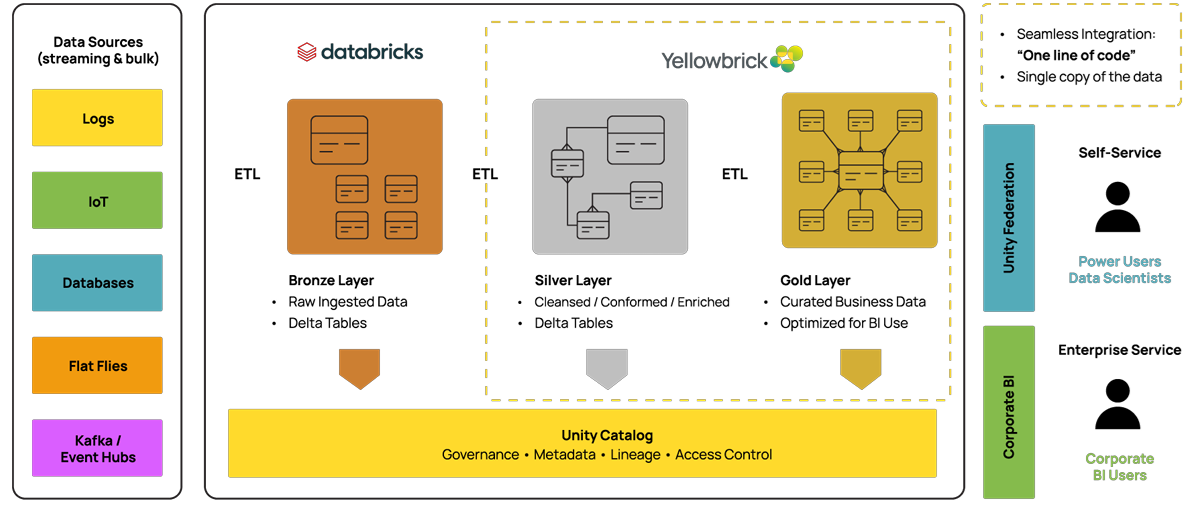
That is exactly what Yellowbrick enables:
- Keep your Databricks workflows and user interface.
- Push curated data to Yellowbrick for fast, cost-effective analytics querying.
- Seamless integration = literally “one line of code”.
The impact:
Yellowbrick accelerates query performance, so teams can act quickly. By reducing perquery costs, organizations can analyze more data for less and give access to everyone.
The Takeaway
If budget constraints prevent full analysis of your critical data, augment Databricks with Yellowbrick to unlock critical BI workloads — without disrupting operations or retraining teams while delivering faster insights and real business impact.
Companies across multiple industries – telecom, insurance, finance, etc. – are asking the hard question: “Is my architecture optimized for value and cost?” If this is you, remember that you do not need to:
- Sacrifice performance to lower costs.
- Overprovision to gain speed.
- Limit who gets value from your data
- Settle for less than the platform’s full potential
You invested in a powerful platform. Now make it work for everyone. Unlock its full potential, open access, and turn your gold layer into a true gold mine.
Yellowbrick is ready to show you how to get value from your data platform. Let’s talk.





