Some of the most challenging datasets from a volume and velocity perspective are network related. Almost every action today, and sometimes no action at all, will generate some kind of network traffic. Common enterprise network data includes IoT, advertising data, PCAP (packet capture), and Netflow. The 2.0 release of the Yellowbrick Data Warehouse includes support for IPv4, IPv6 and MAC addresses. This support enables organizations to take Netflow analysis to a new level.
What is Netflow?
Netflow was developed by Cisco to monitor network traffic. With Netflow, organizations can easily determine where traffic is going and how much traffic is involved from a time or bytes perspective. Many organizations use Netflow to gain insights about user habits and application use, as well as to identify peak network utilization hours and routes suffering from bottlenecks. Think of Netflow as a solution for viewing network metadata, including source and destination IP addresses, ports, which can be used to determine application use, session duration, data volume (bytes transferred), and perhaps most importantly, time stamps.
Netflow has gained popularity as enterprises become more introspective to improve cybersecurity. With the exponential growth of tablets and smartphones behind the network perimeter, security scrutiny must move beyond firewalls to the internal network traffic.
The challenge with monitoring and identifying security threats with Netflow is data volume. Every network interaction generates a log line. Multiply this by the number of devices on the network, the applications per device, and the number of users, and it’s easy to see just how much data is being created. Medium-sized businesses generate 10s of millions of rows of data per day, while a multinational enterprise or government agency easily generates trillions of rows per year. Effective cybersecurity hinges on automating risk detection, using predictive analytics to measure the risk of real-time activity against aggregated historical patterns. Anomalous behavior can then be flagged for an investigator to analyze in more detail. The problem is that data volumes are now so massive that historical data is regularly archived to create space for new data, which means that less historical data is being analyzed quickly, which makes the end results less accurate or less timely. Enterprises are struggling for ways to collect Netflow data in near real time and analyze it against billions or trillions of rows of historical data without making a science project out of it. Enter Yellowbrick.
Yellowbrick IP and MAC address support optimizes analytics by storing data in ways that enable faster, more effective queries. Let’s take a closer look at how.
Faster, more efficient queries of IP data
Most databases don’t have a specific IP address data type. This leaves users storing the data as a varchar or creating a function to convert the data to an integer. Varchars are just strings, so they can’t be treated like a number with order or mathematical functions such as < > or ranges in between. To work an IP address to an integer, you have to perform a conversion, which can add significant time when you’re querying millions or billions of rows. The Yellowbrick database treats IP addresses as their own type, similarly to a number, and supports order and functions. This enables organizations to query ranges with greater than, less than, or between operators without the need to convert data types. With Yellowbrick, you can work with IP addresses in ways similar to the following examples:
select count(*) from netflow_ip where destination_ip > ‘200.200.200.1’
or
select count(distinct source_ip)
from netflow_ip
where destination_ip between ’64.124.9.0’ and ’64.124.9.255’
Enabling rapid data ingest, scanning, and access
Most databases can run a table scan (the most costly activity for most queries) on datasets of one million rows quite quickly. However, as noted above, many Netflow queries now need to scan billions or even trillions of rows. Worse still, it’s increasingly common for multiple large queries to be executing at the same time, resulting in multiple scans at once. Queries can take hours or days to complete, a time lag that is unacceptable for effective cybersecurity.
If you’re reading this, you might already know that Yellowbrick is the world’s first data warehouse designed for flash memory. It can perform table scans at speeds of hundreds of gigabytes per second. A million row table scan is a sub-second activity for Yellowbrick.
Some ways Yellowbrick improves data analytics is by enabling users to define columns for data to be sorted into. Even after the initial sort, sorting continues as new data is added or inserted. By sorting IP addresses in order, organizations can significantly accelerate IP address lookups within a particular range. Yellowbrick also uses zone mapping to tell the database which blocks of the NVMe flash contain which ranges of data.
In the example in Figure 1 below, the IP addresses are sorted into a column. Queries for an address in the 16.0.0.0/1 range only require a scan 1/14th of the data. In a real-world use case, where the dataset is larger and the query is smaller, this approach can deliver a 99% increase in read efficiency. Yellowbrick even displays read efficiency to users to help with data layout and query planning.
Figure 1. Zone Map
A real-world example: massive scalability
To illustrate how well Yellowbrick scales in the face of massive data growth, consider the following example.
We have two tables, one table called netflow and another called netflow_ip. Netflow has the IP address stored as a varchar, like most databases, while netflow_ip uses the Yellowbrick “IP address” data type. The dataset we are using is an open source dataset that has real metrics but the IP addresses have been randomized.
The DLL for the table with the Yellowbrick IP address data type is as follows:
CREATE TABLE netflow_ip(
timestamp timestamp without time zone,
duration real,
source_ip ipv4,
destination_ip ipv4,
source_port integer,
destination_port integer,
protocol character varying(10),
flags character varying(10),
forwarding_status integer,
type_of_service integer,
packets_exchanged integer,
total_bytes bigint,
fg_bg character varying(20)
)
DISTRIBUTE RANDOM
Cluster on (timestamp, source_ip, destination_ip);
Notice that this table clusters on timestamp, source and destination IP. This sorts the table on all three columns, enabling us to get maximum read efficiency if we search by source or destination IP and data ranges.
A Simple IP lookup test
A simple query that counts all the records where an IP address matches with the varchar implementation looks like the following:
select count(*) from netflow where destination_ip = '42.39.197.220'
It takes 4.2 seconds to scan all the rows (14.38 Billion) and count them.
But if we use the Yellowbrick IP address data type, and sort or cluster the data like the DDL above, we see a slash the response time from 4.2 seconds down to 203ms (less than a quarter of a second). A 20x improvement thanks to native flash queries and zone maps!
But how does this implementation scale as you add data? To test scalability, we can start with a table with the same DDL as described above. We then load one week at a time and run the same query each time as we load data.
Our example query looks for IP addresses that accessed the 64.124.9.0/24 range over the entire dataset. Here is the query:
select count(distinct source_ip) from netflow_ip where destination_ip between '64.124.9.0' and '64.124.9.255'
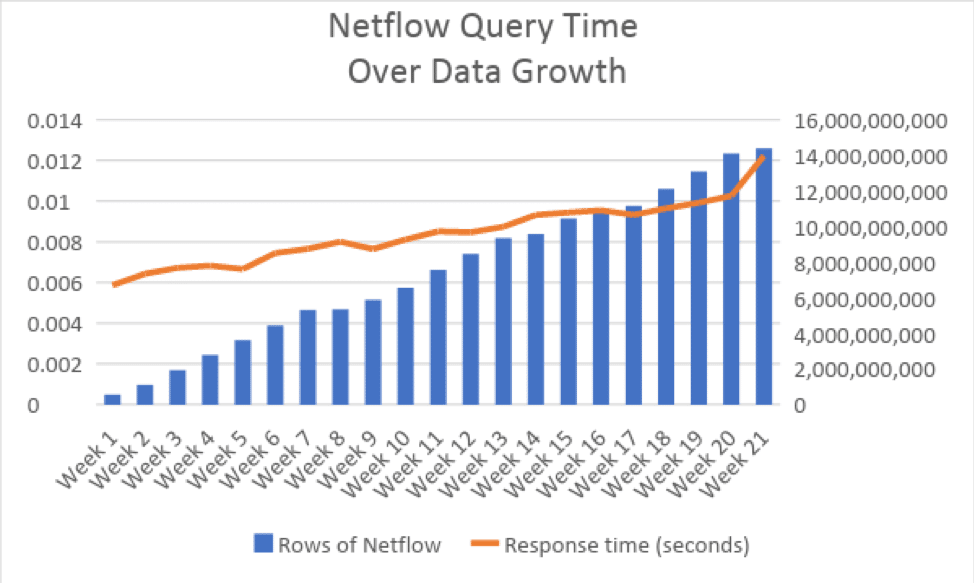
At week one, we have 500 million records. The number grows to the full 14.28 billion by week 21. Response times start at 58.644 milliseconds or .0058 seconds against ~500 million rows and by the time we’ve increased the data size 28x to 14.28 billion, the query response time is 122 milliseconds or .0122 seconds. In short, increasing the number of records queried from 500 million to 14 billion merely doubled the response time, and response times are still under a quarter of a second. Figure 2 plots the response times against the data growth, in seconds.
Figure 2. Yellowbrick completes queries over 28x the size in just double the time (.0122 seconds).
Load data at 10-million rows per second
We’ve shown how Yellowbrick deliver high query performance and scales that performance with data growth. But another area where enterprises struggle with cybersecurity is loading data into the system to begin with. With Yellowbrick, organizations can perform SQL inserts over ODBC, JDBC, and ADO.net. As many are aware, while these protocols are known to be simple and easy to use, they don’t generally move big data sets very quickly. In the case of Yellowbrick, organizations can load about ~150,000 rows a second using these connectors. To enable organizations to load data more rapidly, Yellowbrick created a versatile and high performance data loading tool called ybload. In the next example I will use bare-metal server equipped with SSDs as a source and load data directly into Yellowbrick using ybload 10G networking.
The following test loads about a month’s worth of Netflow data, which amounts to about 308GB.
The data set is loaded at over 10 million rows per second, at about 1GB/s.
At these speeds the entire 308GB dataset is loaded and ready for query in 5 minutes and 15 seconds.
Conclusion
Yellowbrick offers a simple solution to the massive scale and latency requirements associated with production level Netflow analysis. By utilizing the latest hardware and software approaches, Yellowbrick delivers a solution that can ingest Netflow and other data sets at line rate while still serving queries and other application needs. Yellowbrick can make the data available immediately and there are no indexes to create and manage. Data sets over 2 petabytes are easily ingested and managed with a single Yellowbrick cluster occupying only 10U of rack space. If you find yourself questioning any of these performance or scale numbers, seeing is believing. The Yellowbrick team will be happy to set you up with a proof of concept system so you can try it for yourself.